
Note
Click here to download the full example code or to run this example in your browser via Binder
Deduplicating misspelled categories with deduplicate¶
Real world datasets often come with slight misspellings in the category names, for instance if the category is manually input. Such misspellings break many data-analyses steps that require exact matching, such as a ‘GROUP BY’.
Merging the multiple variants of the same category or entity is known as
deduplication. It is performed by the deduplicate() function.
Deduplication relies on unsupervised learning, to find structure in data without providing explicit labels/categories of the data a-priori. Specifically clustering of the distance between strings can be used to find clusters of strings that are similar to each other (e.g. differ only by a misspelling) and hence gives us an easy tool to flag potentially misspelled category names in an unsupervised manner.
An example dataset¶
Imagine the following example: As a data scientist, our job is to analyze the data from a hospital ward. We notice that most of the cases involve the prescription of one of three different medications:
“Contrivan”, “Genericon”, or “Zipholan”.
However, data entry is manual and - either because the prescribing doctor’s handwriting was hard to decipher, or due to mistakes during data input - there are multiple spelling mistakes for these three medications.
Let’s generate some example data that demonstrate this.
import numpy as np
from dirty_cat.datasets import make_deduplication_data
# our three medication names
medications = ["Contrivan", "Genericon", "Zipholan"]
entries_per_medications = [500, 100, 1500]
# 5% probability of a typo per letter
prob_mistake_per_letter = 0.05
duplicated_names = make_deduplication_data(
medications,
entries_per_medications,
prob_mistake_per_letter,
random_state=42, # set seed for reproducibility
)
# we extract the unique medication names in the data & how often they appear
unique_examples, counts = np.unique(duplicated_names, return_counts=True)
# and build a series out of them
import pandas as pd
ex_series = pd.Series(counts, index=unique_examples)
# This is our data:
ex_series.head()
Out:
Ciltrivan 1
Cjntrivan 1
Cmntrivan 1
Coatrivan 1
Cobtvivan 1
dtype: int64
Visualize the data¶
import matplotlib.pyplot as plt
ex_series.plot.barh(figsize=(10, 15))
plt.xlabel("Medication name")
plt.ylabel("Counts")

Out:
Text(33.222222222222214, 0.5, 'Counts')
We can now see clearly the structure of the data: The three original medications are the most common ones, however there are many spelling mistakes and hence many slight variations of the names of the original medications.
The idea is to use the fact that the string-distance of each misspelled medication name will be closest to either the correctly or incorrectly spelled orginal medication name - and therefore form clusters.
We can visualize the pair-wise distance between all medication names¶
Below we use a heatmap to visualize the pairwise-distance between medication names. A darker color means that two medication names are closer together (i.e. more similar), a lighter color means a larger distance. We can see that we are dealing with three clusters - the original medication names and their misspellings that cluster around them.
from dirty_cat import compute_ngram_distance
from scipy.spatial.distance import squareform
ngram_distances = compute_ngram_distance(unique_examples)
square_distances = squareform(ngram_distances)
import seaborn as sns
fig, axes = plt.subplots(1, 1, figsize=(12, 12))
sns.heatmap(
square_distances, yticklabels=ex_series.index, xticklabels=ex_series.index, ax=axes
)
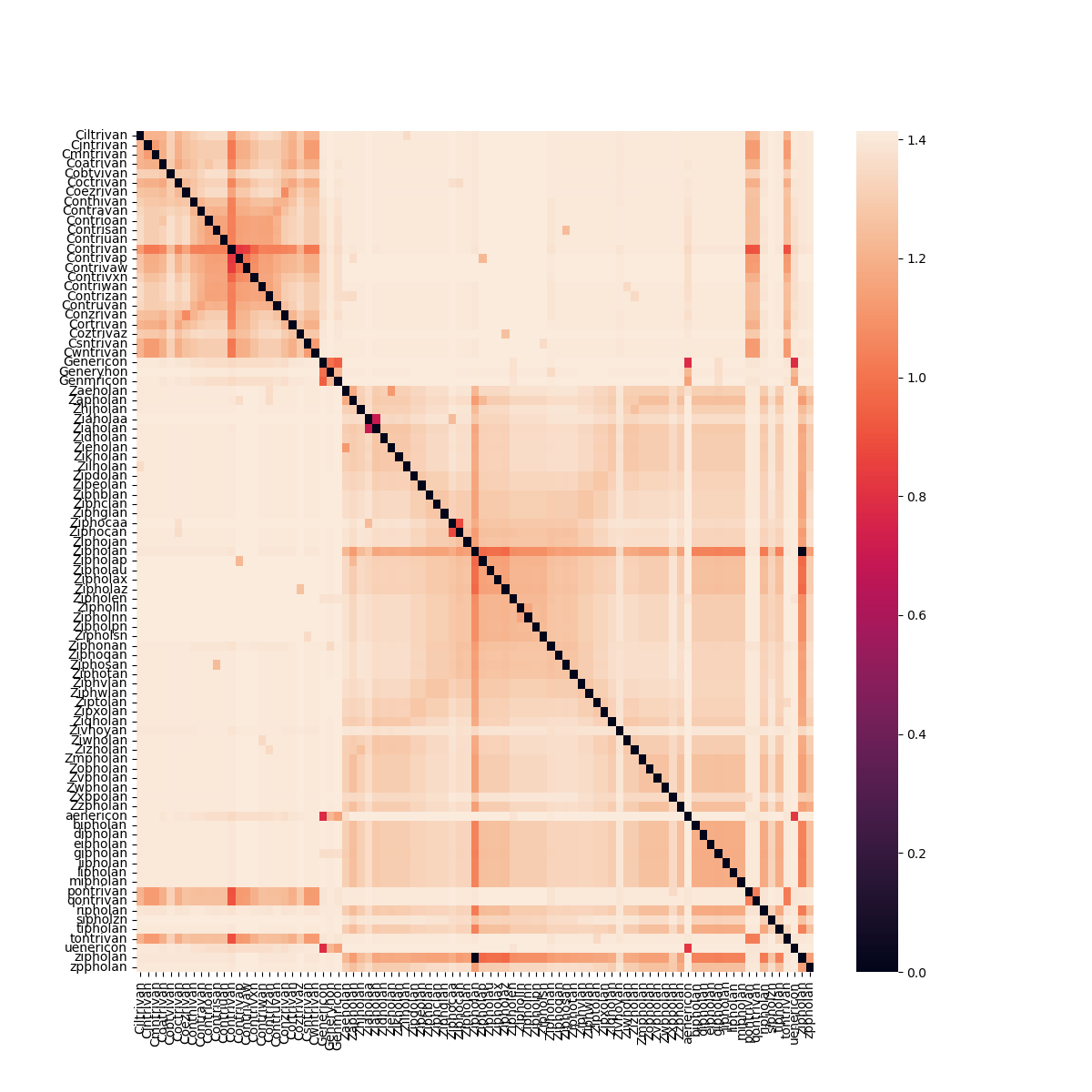
Out:
<AxesSubplot:>
Deduplication: suggest corrections of misspelled names¶
The deduplicate() function uses clustering based on
string similarities to group duplicated names
The number of clusters will need some adjustment depending on the data you have.
If no fixed number of clusters is given, deduplicate() tries to set it automatically
via the silhouette score.
from dirty_cat import deduplicate
deduplicated_data = deduplicate(duplicated_names)
We can visualize the distribution of categories in the deduplicated data:
deduplicated_unique_examples, deduplicated_counts = np.unique(
deduplicated_data, return_counts=True
)
deduplicated_series = pd.Series(deduplicated_counts, index=deduplicated_unique_examples)
deduplicated_series.plot.barh(figsize=(10, 15))
plt.xlabel("Medication name")
plt.ylabel("Counts")
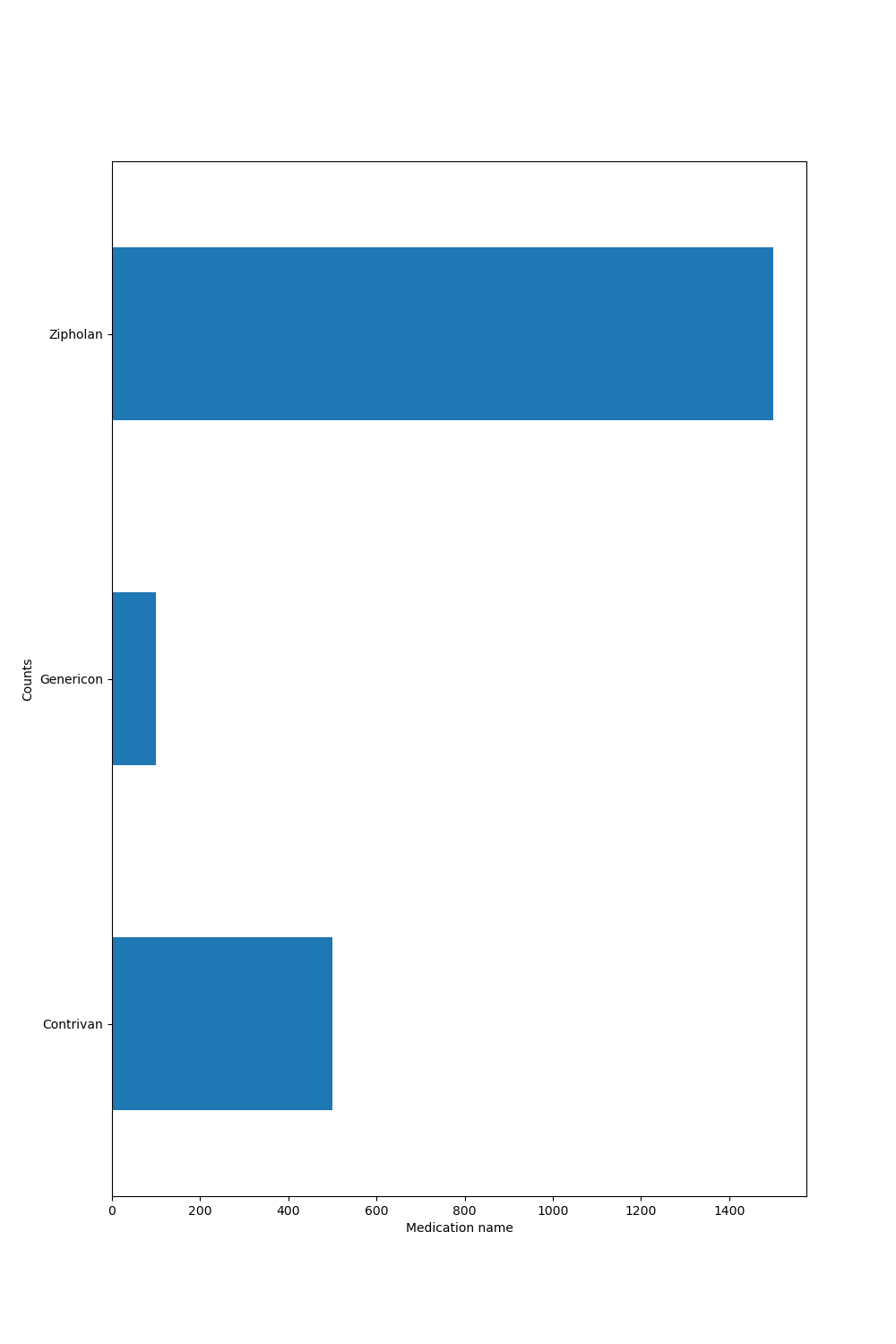
Out:
Text(38.722222222222214, 0.5, 'Counts')
In this example we can correct all spelling mistakes by using the ideal number of clusters as determined by the silhouette score.
However, often the translation/deduplication won’t be perfect and will require some tweaks.
In this case, we can construct and update a translation table based on the data
returned by deduplicate().
It consists of the (potentially) misspelled category names as indices and the
(potentially) correct categories as values.
# create a table that maps original -> corrected categories
translation_table = pd.Series(deduplicated_data, index=duplicated_names)
# remove duplicates in the original data
translation_table = translation_table[~translation_table.index.duplicated(keep="first")]
Since the number of correct spellings will likely be much smaller than the number of original categories, we can print the estimated cluster and their most common exemplars (the guessed correct spelling):
def print_corrections(spell_correct):
correct = np.unique(spell_correct.values)
for c in correct:
print(
f"Guessed correct spelling: {c!r} for "
f"{spell_correct[spell_correct==c].index.values}"
)
print_corrections(translation_table)
Out:
Guessed correct spelling: 'Contrivan' for ['Contrivan' 'Coctrivan' 'Contriwan' 'Conthivan' 'tontrivan' 'Contrivap'
'Cmntrivan' 'Cortrivan' 'Cjntrivan' 'Contrisan' 'qontrivan' 'Contrivxn'
'Csntrivan' 'Conzrivan' 'Cwntrivan' 'Contrizan' 'Coezrivan' 'Contriuan'
'Contrivaw' 'Ciltrivan' 'Contruvan' 'Contravan' 'Coztrivaz' 'Coatrivan'
'Contrioan' 'Cobtvivan' 'pontrivan']
Guessed correct spelling: 'Genericon' for ['Genericon' 'Generyhon' 'Genmricon' 'uenericon' 'aenericon']
Guessed correct spelling: 'Zipholan' for ['Zipholan' 'Ziphglan' 'eipholan' 'Ziphvlan' 'Ziwholan' 'Ziphocan'
'lipholan' 'zipholan' 'Zipholsn' 'Zieholan' 'Zivhoyan' 'Ziphonan'
'Zopholan' 'Ziphoqan' 'Zipholnn' 'Ziphotan' 'Zipeolan' 'Zipholln'
'Zipholap' 'Zzpholan' 'zppholan' 'Zipholau' 'gipholan' 'Zidholan'
'Zaeholan' 'Zwpholan' 'Zipholaz' 'jipholan' 'Zvpholan' 'dipholan'
'Ziphblan' 'Ziptolan' 'Ziphojan' 'Zizholan' 'sipholzn' 'Ziaholan'
'Zipxolan' 'Zipholen' 'Zmpholan' 'Zipdolan' 'Zipholpn' 'Zxppolan'
'Ziphwlan' 'bipholan' 'Ziqholan' 'tipholan' 'Zipholax' 'Zilholan'
'ripholan' 'Ziphclan' 'Ziaholaa' 'Ziphosan' 'Zikholan' 'Ziphocaa'
'Zapholan' 'Zhjholan' 'mipholan']
In case we want to adapt the translation table post-hoc we can easily modified it manually and apply it, for instance modifying the correspondance for the last entry as such:
translation_table.iloc[-1] = "Completely new category"
new_deduplicated_names = translation_table[duplicated_names]
assert (new_deduplicated_names == "Completely new category").sum() > 0
Total running time of the script: ( 0 minutes 3.899 seconds)