
dirty_cat: machine learning with dirty categories¶
dirty_cat facilitates machine-learning with non-curated categories: robust to morphological variants, such as typos. See examples, such as the first one, for an introduction to problems of dirty categories or misspelled entities.
TableVectorizer: a transformer to easily turn a pandas
dataframe into a numpy array suitable for machine learning – a default
encoding pipeline you can tweak.
GapEncoder, scalable and interpretable, where each encoding dimension corresponds to a topic that summarizes substrings captured. ExampleSimilarityEncoder, an enhanced one-hot encoder able to capture the string similarities in the data. ExampleMinHashEncoder, very scalable, suitable for big data. Example
fuzzy_join(), approximate matching using morphological similarity. ExampleFeatureAugmenter, a transformer for joining multiple tables together. Example
deduplicate(), merging categories of similar morphology (spelling).
- Installing:
$ pip install --user --upgrade dirty_cat
Usage examples¶
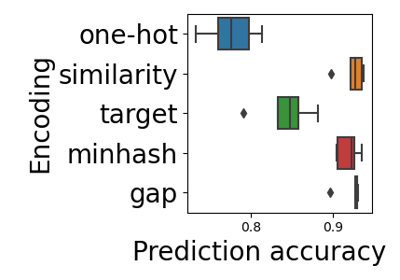
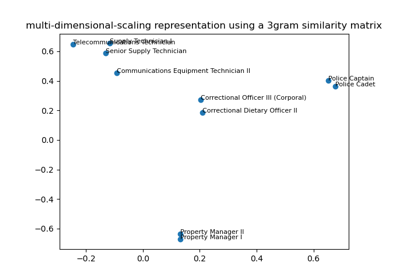
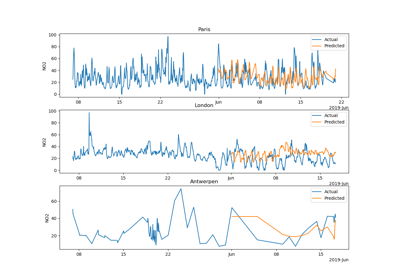
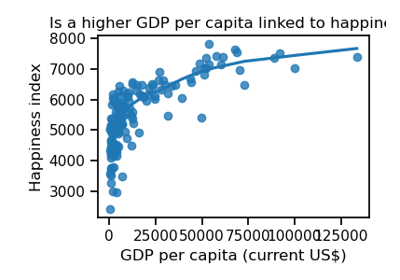
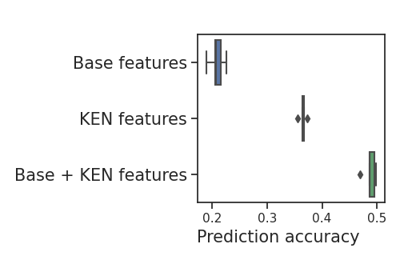
For a detailed description of the problem of encoding dirty categorical data, see Similarity encoding for learning with dirty categorical variables [1] and Encoding high-cardinality string categorical variables [2].
API documentation¶
Vectorizing a dataframe¶
Automatically transform a heterogeneous dataframe to a numerical array. |
Dirty category encoders¶
Constructs latent topics with continuous encoding. |
|
Encode string categorical features by applying the MinHash method to n-gram decompositions of strings. |
|
Encode string categorical features to a similarity matrix. |
|
Encode categorical features as a numeric array given a target vector. |
Other encoders¶
Transforms each datetime column into several numeric columns for temporal features (e.g year, month, day...). |
Joining tables¶
Join two tables with categorical columns based on approximate matching of morphological similarity. |
Augment a main table by automatically joining multiple auxiliary tables on it. |
Deduplication: merging variants of the same entry¶
Deduplicate categorical data by hierarchically clustering similar strings. |
Data download and generation¶
Fetches the employee salaries dataset (regression), available at https://openml.org/d/42125 |
|
Fetches the medical charge dataset (regression), available at https://openml.org/d/42720 |
|
Fetches the midwest survey dataset (classification), available at https://openml.org/d/42805 |
|
Fetches the open payments dataset (classification), available at https://openml.org/d/42738 |
|
Fetches the road safety dataset (classification), available at https://openml.org/d/42803 |
|
Fetches the traffic violations dataset (classification), available at https://openml.org/d/42132 |
|
Fetches the drug directory dataset (classification), available at https://openml.org/d/43044 |
|
Fetches a dataset of an indicator from the World Bank open data platform. |
|
Get the supported aliases of embedded KEN entities tables. |
|
Helper function to search for KEN entity types. |
|
Download Wikipedia embeddings by type. |
|
Returns the directory in which dirty_cat looks for data. |
|
Duplicates examples with spelling mistakes. |
About¶
dirty_cat is a young project born from research. We really need people giving feedback on successes and failures with the different techniques on real world data, and pointing us to open datasets on which we can do more empirical work. dirty-cat received funding from project DirtyData (ANR-17-CE23-0018).